在很多界面里,信息并不总是以文字出现,有时会以图标按钮、角标数字、红点提示、状态图形、促销 banner、流程示意图、数据图表等形式出现,对于视觉正常的用户,这些内容看起来都很直观,通常可以通过颜色、形状、位置与层级进行区分。但一旦用户无法依赖视觉进行正常浏览,那么这些信息就会突然断层。界面尽管仍然存在,但关键含义却像被抽走了一部分一样。
文本替代要做的事,就是把这类完全依赖视觉传递的信息,用文字补齐,让信息可以被用户从另外一条通道理解。它不是给图片写一段外观描述,而是把图片或图形在当前场景里承担的意义交代清楚。用户不必完全借助于眼睛,也能知道这是什么、它表达了什么、点了会发生什么。
文本替代最直接的受益者,是盲人和重度低视力用户,他们通常会借助屏幕阅读器来浏览和操作界面。对于这些用户而言,文本替代决定了界面产品是否完整。如果没有文本替代,他们借助读屏器听到的内容,可能只是“按钮”、“图像”、“未标注”,这样用户很难形成可靠的理解,更谈不上顺利完成任务。
文本替代的重要意义并不局限盲人和重度低视力用户。当图片加载失败、网络不佳、强光下看不清、正常视力的用户也只能通过键盘操作、接收语音提示的方式快速定位信息,在这种情境下,文字表达就会变得极为重要。文本替代让同一份信息能够被转成语音、盲文或其他形式,这也是它被放在可感知里的原因。
要想真正讲清文本替代,就绕不开屏幕阅读器。因为屏幕阅读器是检验文本替代是否有效的一把尺子。
1. 屏幕阅读器
屏幕阅读器是一种辅助技术。它把屏幕上的内容转化为语音或盲文,让用户即使不依赖视觉,也能理解界面并完成操作。它看上去像是在朗读页面,但它并不会像人一样看图识字,更不会理解渐变、阴影、对齐、留白这类纯粹的视觉表现。
屏幕阅读器真正读取的,是浏览器与系统提供的无障碍语义信息。你可以把这层信息理解为界面的语义骨架,它决定了用户“听到的界面”长什么样。通常,这套语义会包含几类关键内容。
1. 元素类型。读屏器会告诉用户当前对象是按钮、链接、输入框、标题、列表项,还是图像。
2. 元素名称。也就是读屏器实际朗读出来的那句话。图标按钮往往会被读成搜索、返回、更多操作之类的名称;图片则通常依赖其替代文本来提供可读的内容。
3. 状态信息。已选中、不可用、展开或收起、是否存在错误、是否有未读数量,这些都属于状态。对视觉用户而言,它们可能只是颜色或样式的轻微变化;但对读屏用户而言,若没有用语义明确表达,用户就无从得知界面发生了什么。
4. 结构与顺序。读屏器通常沿着可聚焦元素的顺序前进,从一个可操作对象移动到下一个对象。视觉用户可以同时扫视多个信息点,而读屏用户更像沿着一条线索逐步推进,一旦顺序混乱,用户就很容易在听觉路径里迷失方向。
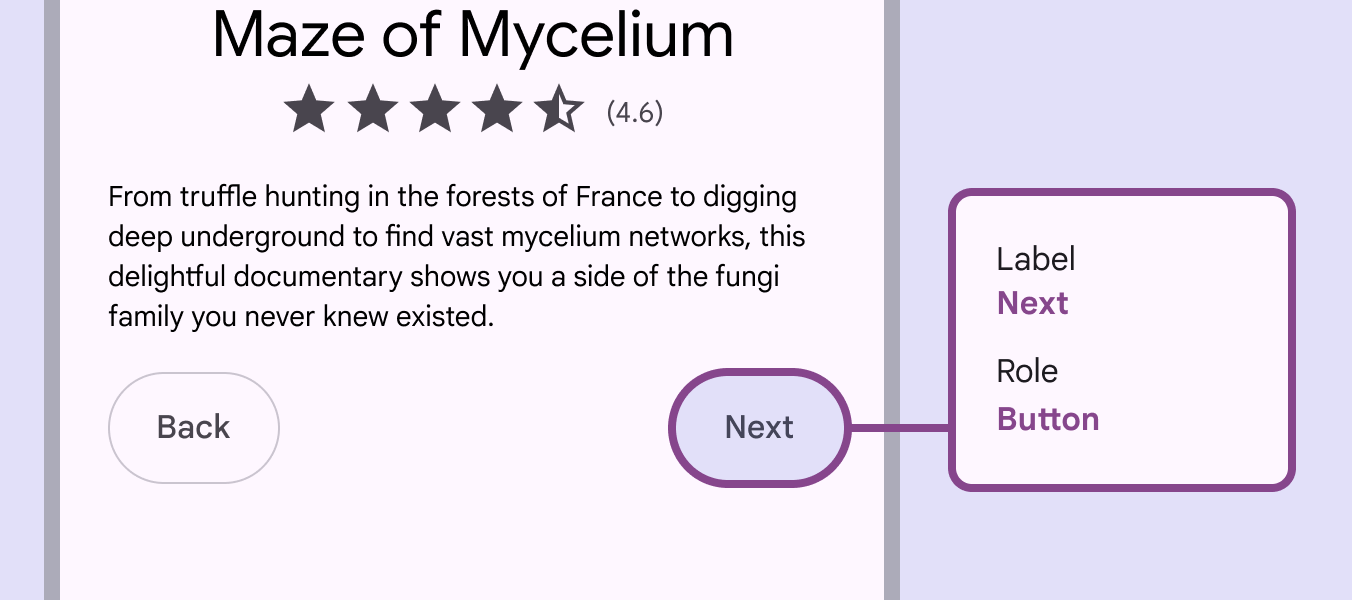
M3无障碍规范中,关于按钮可被读取的标签元素
屏幕阅读器的工作机制,为我们带来一个非常重要的结论:屏幕阅读器读的不是你画出来的画面,而是你和研发共同交付给浏览器的语义信息。文本替代正是在这层语义上补齐缺失的含义,让界面在读屏的路径里不出现空白与断点。
2. 文本替代
有了对屏幕阅读器的基础了解,我们回到WCAG可感知:文本替代的讲解。
在 WCAG 的可感知原则下,文本替代的要求其实可以归结为一句话:只要某段内容不是以文字呈现,却承载了信息或功能,就必须给它配上一份等价的文字表达,让这些信息能被转换成用户需要的形式。
这里有两个要点,需要特别注意。
第一,所谓等价,并不是说外观要被“翻译”出来,而是说信息要等价。视觉用户能理解什么、能据此做出什么操作,读屏用户也应该获得同样的理解与行动依据。
第二,非文本内容也远不止图片。图标按钮、角标、红点、状态图形、图表、信息图、以及图片里写着的文字说明,都在这个范围之内。
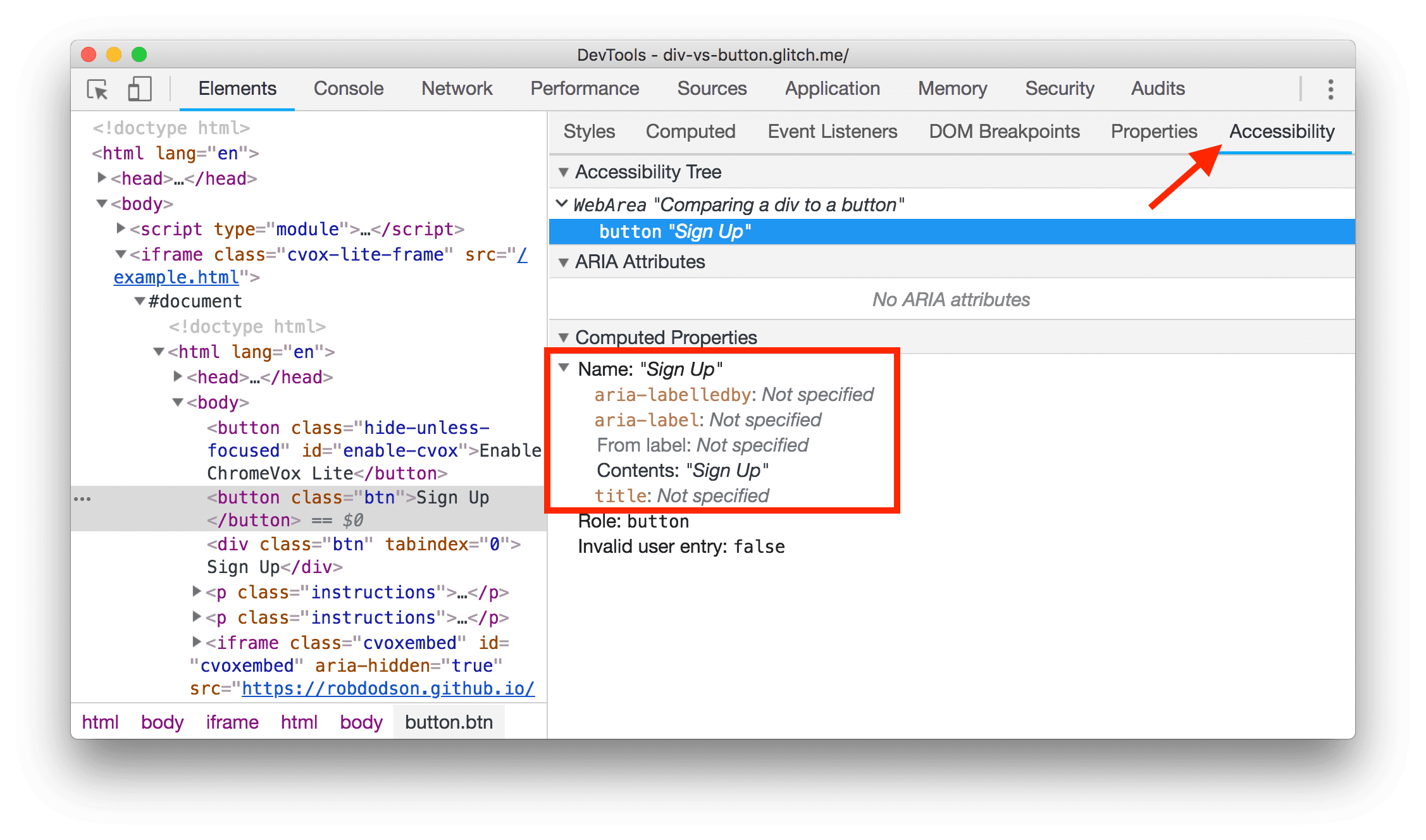
在 Chrome 的开发者工具中查看元素的无障碍名称,研发就是将文本替代添加在这里
为了让写法明确,我们需要最先确定一件事:这个元素在当前界面里扮演什么角色。角色不同,写法就不同。